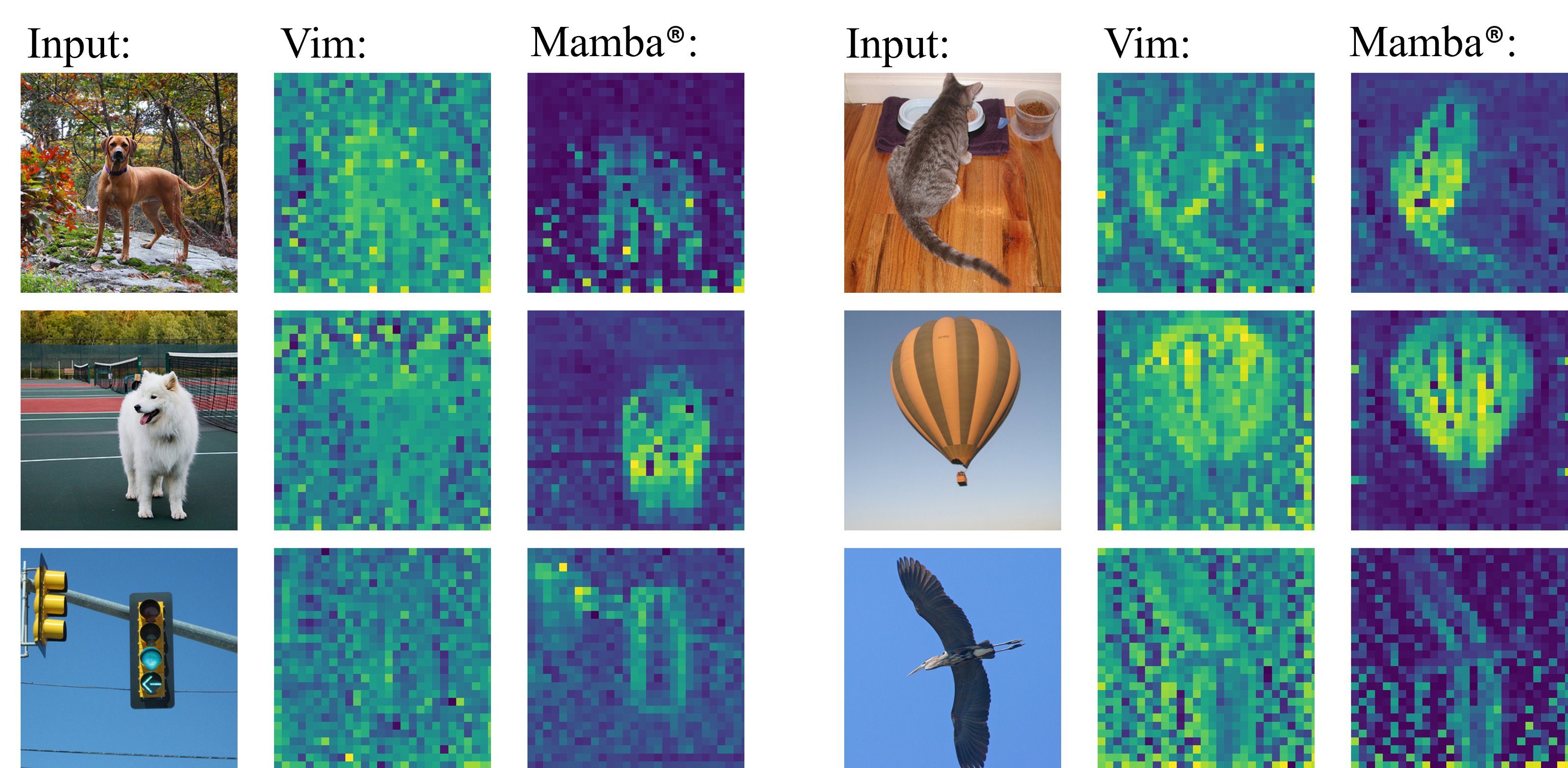
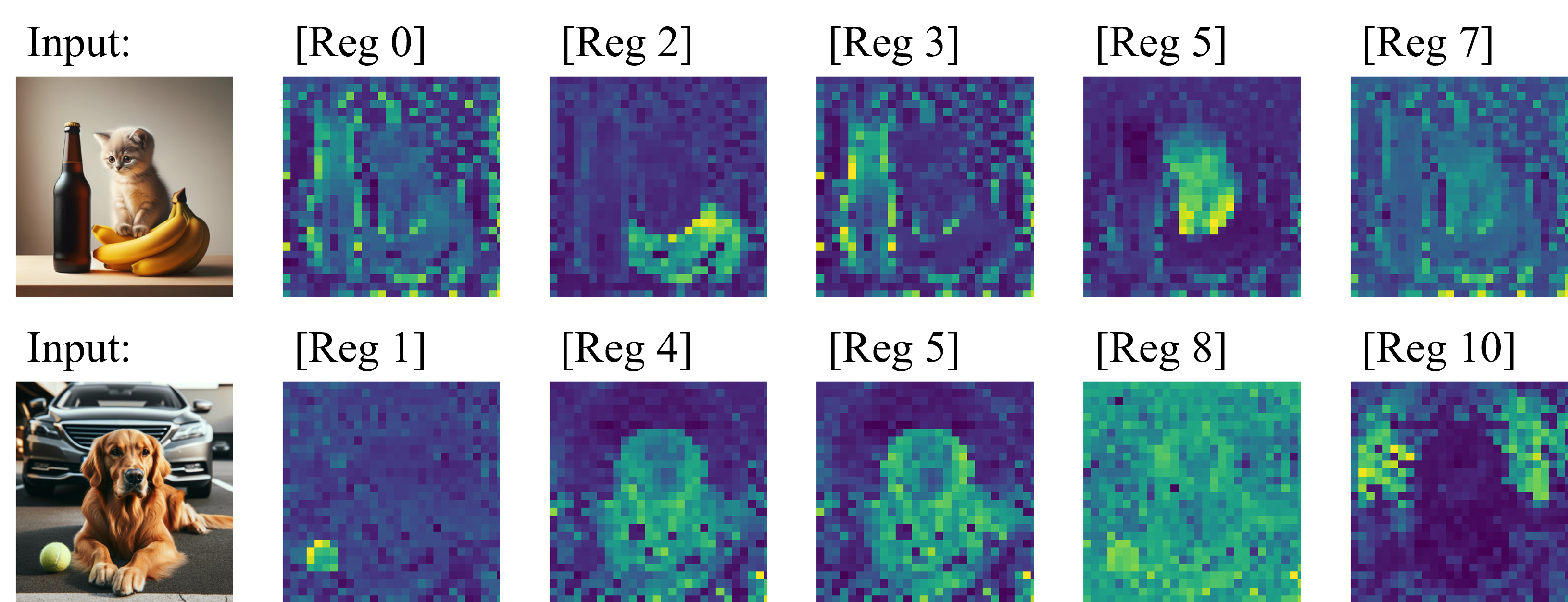
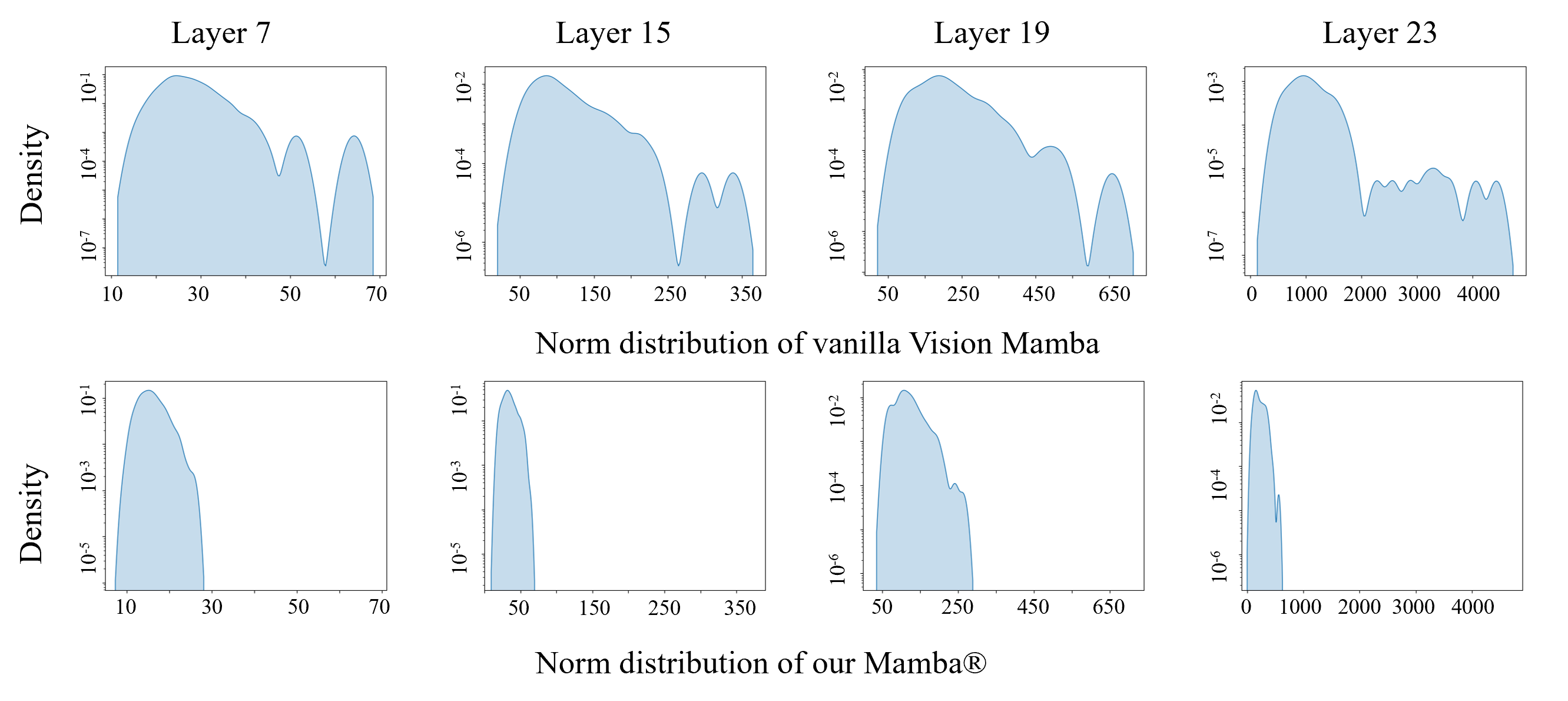
Similar to Vision Transformers, this paper identifies artifacts also present within the feature maps of Vision Mamba. These artifacts, corresponding to high-norm tokens emerging in low-information background areas of images, appear much more severe in Vision Mamba---they exist prevalently even with the tiny-sized model and activate extensively across background regions. To mitigate this issue, we follow the prior solution of introducing register tokens into Vision Mamba. To better cope with Mamba blocks' uni-directional inference paradigm, two key modifications are introduced: 1) evenly inserting registers throughout the input token sequence, and 2) recycling registers for final decision predictions. We term this new architecture Mamba®. Qualitative observations suggest, compared to vanilla Vision Mamba, Mamba®'s feature maps appear cleaner and more focused on semantically meaningful regions. Quantitatively, Mamba® attains stronger performance and scales better. For example, on the ImageNet benchmark, our Mamba®-B attains 82.9% accuracy, significantly outperforming Vim-B's 81.8%; furthermore, we provide the first successful scaling to the large model size (i.e., with 341M parameters), attaining a competitive accuracy of 83.2% (84.5% if finetuned with 384x384 inputs). Additional validation on the downstream semantic segmentation task also supports Mamba®'s efficacy.